


On Wednesday, March 13, 2019, Facebook, Messenger and Instagram were down for almost 14 hours.
It is believed to be the biggest interruption ever suffered by the 2.32 billion users social network. People took to Twitter to express their outcry and soon #FacebookDown was trending.
According to downdetector.com, the outage was reported in the United States, Europe, Japan, Manila, Australia and New Zealand.
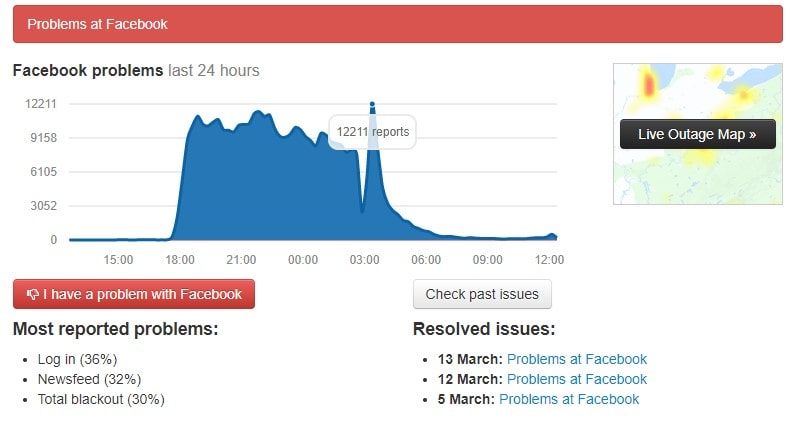
image source: downdetector.com
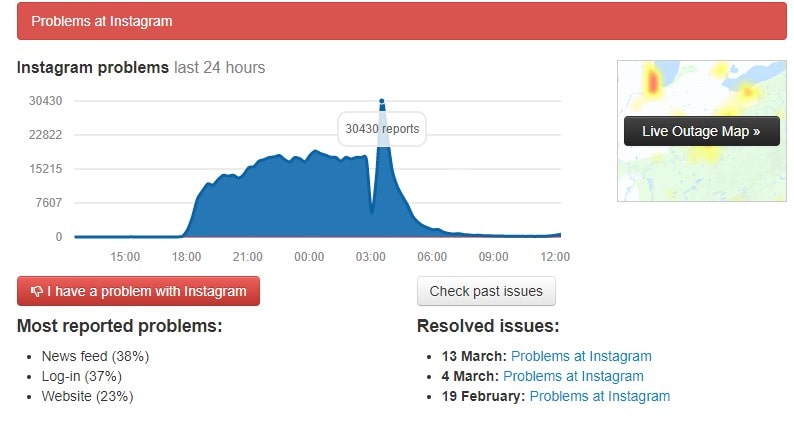
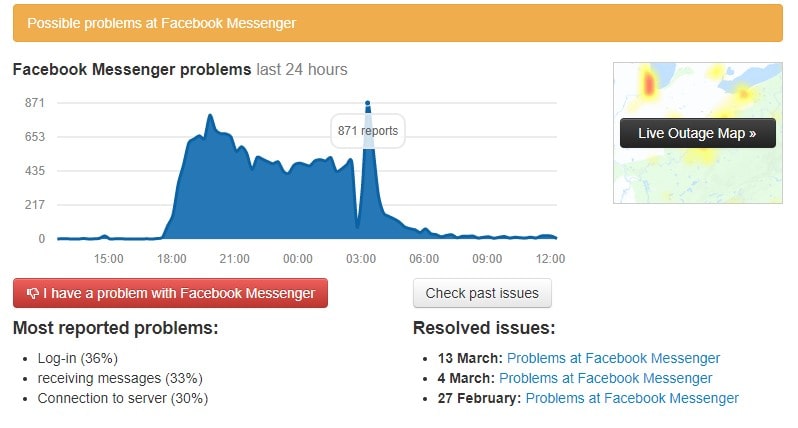
At the time of this article, the three social media giants are back to business as usual.
Facebook hasn’t issued a statement explaining the source of the outage yet.
Yesterday at 9 p.m., Facebook expressed awareness related to the situation and cleared the rumours regarding a virus attack:
We’re focused on working to resolve the issue as soon as possible, but can confirm that the issue is not related to a DDoS attack.
— Facebook (@facebook) 13 martie 2019
Some experts suggest an accidental BGP routing leak from a European ISP to a major transit ISP, while others point to a mistake in programmatic automation.
More likely a cause of this nature would be due to a mistake in programmatic automation and various health checks that they perform to ensure optimal functionality for users. If I had to conjecture, I would suspect that the outage today was likely due to a flaw in the code that controls such functions on a high-level business wise. Consider that the impact was across several Facebook-owned services, therefore, the likelihood of them trying to be efficient in their code and its centralization for many services is more likely the root cause.
Tom Thomas, a Tulane University adjunct faculty member (via Techcrunch.com)
It is estimated that yesterday’s outage cost Facebook around $76 million in advertising revenue.

















